
Most finance teams do not need another disconnected reporting workaround.
They also do not need a simple “dump the data into AI” approach that generates commentary without understanding the underlying financial model, reporting structures, dimensions, hierarchies, transactions, finance logic or broader business context.
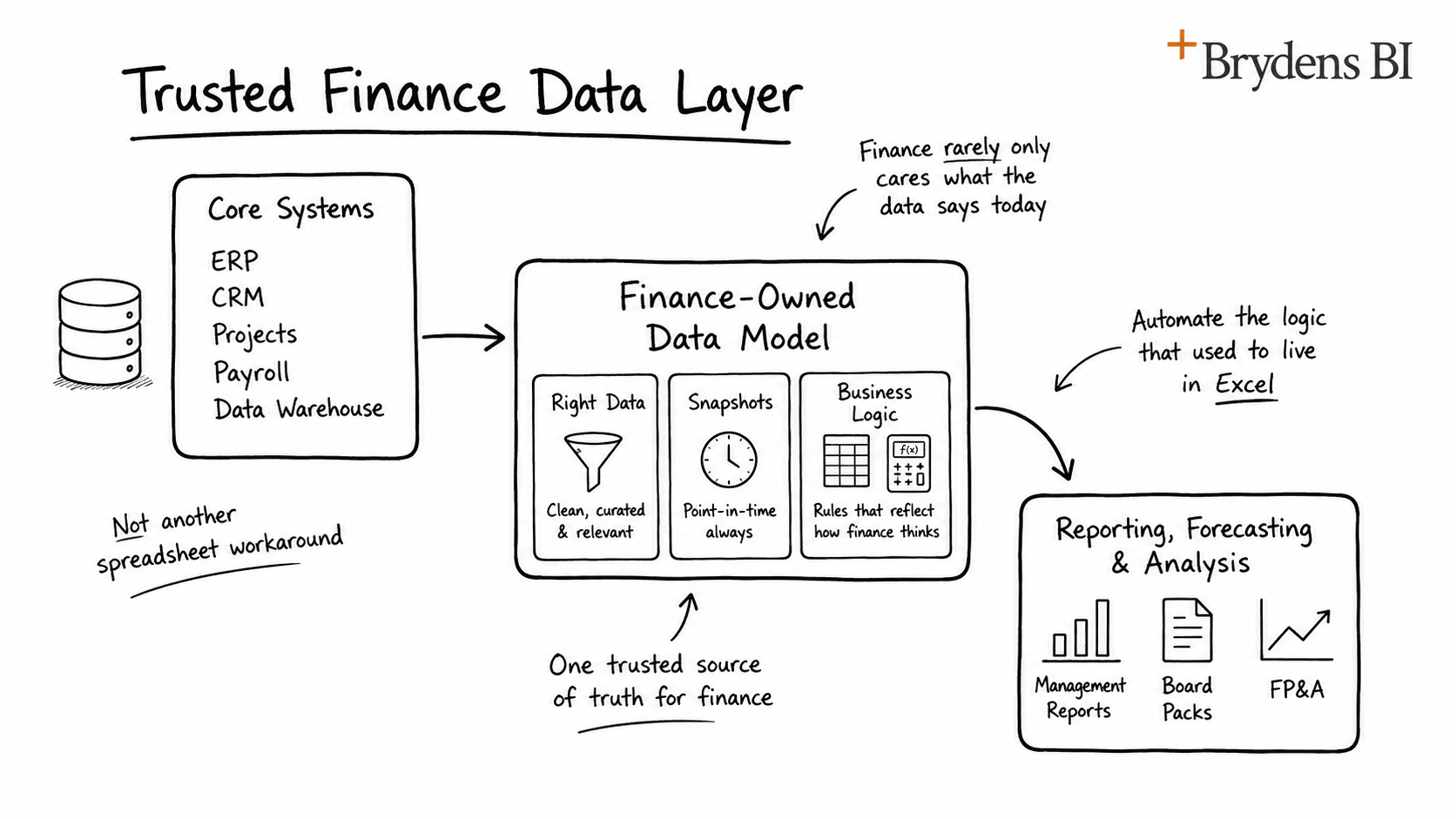
Finance teams already have important systems in place. They may use an ERP such as NetSuite, Sage Intacct or Microsoft Dynamics 365. They may also rely on HubSpot, project systems, payroll platforms, operational databases, Power BI reports, and in many cases, an internal enterprise data warehouse.
These systems hold valuable data. But they do not always give finance the controlled, finance-ready view required for management reporting, forecasting, board reporting, FP&A and practical AI-assisted analysis.
That is why many finance teams still rely on Excel after the data has left the source system. They export, reshape, map, adjust, enrich and reconcile data before it becomes useful for decision-making.
The problem is rarely the existence of Excel itself. Excel is flexible, familiar and valuable. The problem is when critical finance logic only exists in disconnected workbooks, manual files and reporting packs that are difficult to govern, reuse or explain.
A trusted finance data layer helps solve this problem.
It connects the core systems that already run the business into a finance-owned data model that captures the right data, keeps the right history and applies the right business logic consistently. That same foundation also makes AI more useful, because AI-assisted commentary, variance analysis, key driver identification and scenario support can be grounded in finance-approved data, structures, context and definitions.
What is a trusted finance data layer?
A trusted finance data layer is a controlled model that sits between core business systems and the reporting, planning and analysis outputs used by finance.
It is not designed to replace the ERP, CRM, data warehouse or operational systems. Instead, it extends them by creating a finance-ready view of the data.
This distinction matters.
An ERP is built to process transactions. A CRM is built to manage customer and pipeline activity. A project system is built to manage delivery. An enterprise data warehouse may be built to consolidate data across the organisation.
Finance, however, often needs something more specific.
Finance needs a curated subset of data that supports reporting, forecasting, analysis and decision-making. That usually includes actuals, budgets, forecasts, pipeline, project performance, workforce assumptions, management hierarchies, reporting structures, finance KPIs and business-specific adjustments.
The purpose is not to replicate every source system in full. The purpose is to create a trusted model that finance can use to explain performance.
Finance does not need every data point
One of the common mistakes in finance reporting architecture is assuming that more data automatically means better insight.
For finance, this is rarely true.
The finance team does not usually need every field from every system. It needs the data that is relevant to reporting, planning, forecasting and performance management.
That might mean taking selected actuals from the ERP, selected pipeline data from the CRM, selected delivery data from project systems and selected assumptions from workforce or operational platforms. It may also mean using an internal data warehouse as a source, then applying finance-specific logic on top of it.
The value is created when these inputs are shaped into a model that reflects how the business actually reports and manages performance.
That means aligning the data to finance-owned structures such as management reporting hierarchies, board reporting categories, account mappings, cost centre groupings, project classifications, revenue categories and forecast versions.
Without this layer, finance teams often have to recreate these structures manually each month.
The hidden risk: business logic trapped in Excel
In many organisations, Excel is not just used for analysis. It is used to hold business logic.
That logic may include mappings, calculations, adjustments, reclassifications, exclusions, allocations, overrides, KPI definitions and reporting hierarchies. These rules are often specific to the way the business operates, which means they may not belong neatly inside the ERP or CRM.
The issue is not that this business logic exists. It is essential.
The issue is when it only exists in spreadsheets.
When key logic is maintained manually in Excel, reporting becomes more fragile. Different files can use different mappings. Adjustments can be applied inconsistently. Forecast versions can become difficult to trace. Month-end reporting can depend on knowledge held by one or two people.
A trusted finance data layer gives finance a central place to manage this logic.
At Brydens BI, we help finance teams automate and maintain a single, central source of truth for business-specific adjustments, mappings, calculations and enrichments that are often entered manually in Excel.
This gives finance greater control without removing finance ownership.
The finance team can still define the rules. The difference is that those rules are applied consistently, transparently and repeatably across reporting, forecasting and analysis.
Why snapshots matter for finance reporting
Many data models focus on the current state of the data.
That is useful for operational reporting, but finance often needs more than a live view.
Finance rarely only cares about what the data says today. It also needs to know what the business believed at a particular point in time.
For example, finance may need to understand what the sales pipeline looked like at month end, what the forecast was before management adjustments, what the board pack showed last quarter, or how budget assumptions changed between versions.
These questions cannot always be answered from a live source system view.
If the pipeline changes every day, the current CRM view may not show what the pipeline looked like when the month-end forecast was prepared. If a budget assumption is overwritten, the current planning file may not show what was originally submitted. If a board pack is updated after review, finance may need to know which version was actually presented.
This is why a trusted finance layer should preserve the right history and snapshots.
The point is not to store everything forever. The point is to keep the versions and point-in-time views that matter for reporting, governance and decision-making.
This may include month-end pipeline snapshots, submitted forecast versions, approved budgets, historic reporting hierarchies, board pack outputs, adjustment history and assumption changes.
When this history is preserved properly, finance can explain not only what changed, but when it changed and why.
Connecting internal data warehouses into finance-owned models
Many organisations already have an internal finance data warehouse. This can be a strong foundation, but it does not always remove the need for a finance-owned model.
An enterprise data warehouse is often designed to serve multiple functions. It may consolidate raw data, standardise source system feeds and support broad reporting requirements across the organisation.
Finance reporting and planning usually requires an additional layer of interpretation.
For example, the internal data warehouse may hold customer, transaction, project and pipeline data. But finance may still need to apply management reporting structures, budget categories, forecast classifications, consolidation logic, allocation rules and board reporting definitions.
A finance-owned model can sit on top of the internal data warehouse and convert enterprise data into finance-ready outputs.
This avoids duplicating the warehouse while giving finance the controlled layer it needs for reporting, forecasting and analysis.
From manual reporting packs to governed finance models
The monthly reporting process often reveals where the real data problems are.
They appear when finance has to export data from multiple systems, apply mappings in Excel, copy adjustments between files, reconcile versions and rebuild commentary after the numbers change.
These are not just process inefficiencies. They are control issues.
A governed finance model helps move these recurring tasks into a more reliable structure. It creates a consistent way to capture data, apply business logic, preserve history and produce reporting outputs.
This supports management reporting, consolidation, budgeting, forecasting, board reporting, project reporting, pipeline analysis and FP&A.
More importantly, it gives finance confidence in the numbers.
The finance team can spend less time asking whether the report is correct and more time explaining what the results mean.
What Brydens BI helps finance teams build
At Brydens BI, we help finance teams connect core systems, including ERPs, CRMs, operational platforms and internal data warehouses, into finance-owned data models for reporting, forecasting and analysis.
These models are designed to support reporting, forecasting and analysis in a way that finance can trust, maintain and explain.
We help automate the business-specific logic that often sits in Excel, including adjustments, mappings, calculations and enrichments. We also help create the structures needed to preserve point-in-time snapshots, historic versions and reporting history.
The result is a trusted finance layer that captures the right data, keeps the right history and applies the right business logic consistently.
This does not replace the systems that already run the business.
It makes them more useful for finance.
Better finance insight needs more than connected data
Connecting data is only the first step.
Finance teams also need the data to be curated, governed, enriched and preserved in a way that supports how the business actually reports and plans.
A trusted finance data layer helps turn source system data into finance-ready insight.
It gives finance a central source of truth for reporting logic. It reduces reliance on manual spreadsheet workarounds. It preserves the snapshots and versions needed to explain performance over time. And it creates a stronger foundation for management reporting, forecasting, board packs and FP&A.
For CFOs and finance leaders, the opportunity is clear.
The goal is not simply to have more data.
The goal is to create a finance-owned model that helps the business understand performance, make better decisions and trust the numbers behind them.
Why a trusted finance data layer also increases the value of AI
A trusted finance data layer also creates a much stronger foundation for AI in finance.
AI tools are most useful when they can work with structured, governed, and aligned data that reflects how the business actually reports performance. If the underlying data is fragmented across exports, spreadsheets, source systems and manual adjustments, AI may be able to generate commentary, but it will not necessarily be working from a reliable version of the truth.
Once finance has a controlled layer that captures the right data, preserves the right snapshots and applies business logic consistently, the potential value of AI increases significantly. AI can then be used to help explain variances, analyse trends, generate commentary, compare forecast versions, identify exceptions and support scenario analysis using finance-approved data and definitions.
This is also why Brydens BI has developed an adjacent AI layer for trusted finance data. It is deliberately practical: AI-assisted commentary, variance analysis, key driver identification and bespoke finance visuals that sit alongside established finance environments, rather than replacing them.
This is not a simple “dump the data into AI” approach. It uses the underlying financial model, dimensions, hierarchies, transactions, user-provided context and broader business context to produce outputs that are grounded in how the organisation actually reports and manages performance.
The opportunity is strongest when AI can work with the trusted finance data, reporting structures, dimensionality, hierarchies and business logic that already exist in the finance environment. This helps AI produce outputs that are more finance-aware, more explainable and more useful for real reporting and planning processes.
For example, an adjacent AI layer can help finance teams:
- generate faster first drafts of finance commentary for review, refinement and approval;
- explain Actual v Budget, Actual v Plan and forecast movements more clearly;
- identify key drivers behind variances and trends;
- use finance model structures, notes and supporting detail to produce more relevant explanations; and
- create targeted finance visuals that help answer specific management questions.
This does not remove the need for financial judgment, governance or review. It makes those activities more effective by giving AI a better foundation to work from.
In that sense, a trusted finance data layer is not only valuable for today’s reporting and forecasting. It also prepares the finance function for a more practical, controlled use of AI in the future.
Build a trusted finance layer around your existing systems
If your finance team is still relying on manual exports, spreadsheet adjustments or disconnected reporting packs, Brydens BI can help you design a finance-owned data model that connects the right systems, preserves the right history and applies business logic consistently.
Talk to Brydens BI about finance data layer design, reporting, forecasting and FP&A.
Common Finance Data Layer Questions
What is a finance data layer?
A finance data layer is a controlled model that brings together finance-relevant data from core business systems and applies the logic needed for reporting, planning and analysis. It usually sits between source systems, such as ERPs and CRMs, and finance outputs such as management reports, forecasts and board packs.
How is a finance data layer different from a data warehouse?
A data warehouse may store and standardise data across the organisation. A finance data layer is more specific. It curates the subset of data finance needs, applies finance-owned business logic, preserves reporting history and supports outputs such as management reporting, budgeting, forecasting and FP&A.
Why do finance teams still use Excel after implementing an ERP?
Finance teams often use Excel because ERPs do not always hold the business-specific mappings, adjustments, enrichments and reporting structures needed for management reporting. Excel offers flexibility, but when critical reporting logic is stored only in spreadsheets, the process can become manual and difficult to govern.
Why are snapshots important in finance reporting?
Snapshots allow finance teams to understand what the data looked like at a specific point in time. This is important for month-end pipeline reporting, forecast submissions, board reporting, budget versions and tracking how assumptions changed over time. If an important update is given to the board, it is critical that finance can reproduce it or answer questions using the same information if questions arise.
What business logic should be centralised in a finance model?
Finance teams often centralise account mappings, cost centre groupings, reporting hierarchies, KPI definitions, allocation and elimination rules, forecast assumptions, adjustment logic, project classifications and board reporting categories.
This becomes especially important when business structures change. For example, a finance team may need to report using both old and new department structures during a transition period. Or a group may need to consolidate subsidiaries that use different systems, charts of accounts or reporting formats.
Centralising this logic reduces manual rework and helps ensure that the same rules are applied consistently across reporting, forecasting and analysis.