
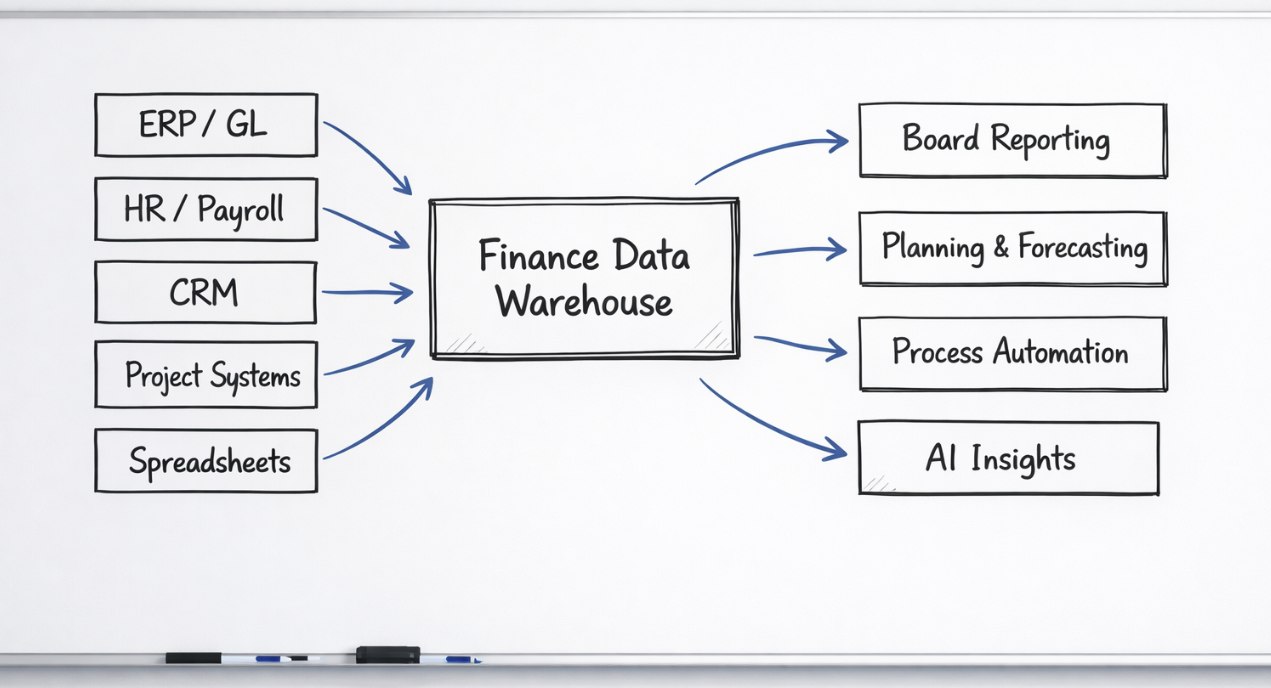
At Brydens BI, one of the most common things we see in finance teams is not a lack of data. It is the opposite.
There is data in the ERP. Data in payroll and HR systems. Data in CRM platforms. Data in project systems. Data in operational systems. Then there are all the spreadsheets built over time to bridge the gaps between them. Before long, reporting slows down, definitions drift, and more of the finance team’s time is spent stitching numbers together than actually analysing them.
That is where a Finance Data Warehouse becomes important.
In our experience, a Finance Data Warehouse works best when it gives Finance a single trusted, governed environment that brings together financial, workforce, and operational data into a structure designed for reporting, consolidation, planning, forecasting, and automation.
The key point is this: a Finance Data Warehouse is not just somewhere to store data. It is a curated finance model. It should make close, reporting, planning, and forecasting faster, more reliable, and easier to explain. And if it is designed properly, it also becomes the foundation for automation and the careful introduction of AI.
What a Finance Data Warehouse is, and what it is not
At a practical level, a Finance Data Warehouse is a structured, governed data layer designed specifically for Finance.
It should support:
- periodic and on-demand reporting
- management and board reporting
- budgeting and rolling forecasts
- multi-entity consolidation
- allocations and adjustments
- drill-through and auditability
- scenario modelling
What it should not be is a generic dumping ground for data.
We often see confusion here. A data lake and a Finance Data Warehouse are not the same thing. A data lake may be useful for storing large volumes of broad enterprise data, but that does not automatically give Finance a trusted reporting and planning environment. In our view, the Finance Data Warehouse is the curated, finance-ready layer that sits closer to the actual decision-making needs of CFOs, finance leaders, and boards.
It is also not just a dashboarding layer. A dashboard can present numbers nicely, but if the underlying mappings, hierarchies, and business rules are inconsistent, all you have done is make inconsistent reporting look more polished.
A proper Finance Data Warehouse is where the meaning of the numbers is defined, controlled, and maintained.
The 7 core components every Finance Data Warehouse should contain
1. Core financial actuals
At the centre of the model should be the core financial data: actual GL transactions, chart of accounts, entities, cost centres, departments, currencies, and accounting periods.
This sounds obvious, but in practice it is often not handled well. We regularly see environments where only summary-level data is available, or where the structure is too limited to support the real questions finance needs to answer.
In our experience, Finance needs enough granularity and enough structure to support both recurring management views and deeper drill-through when needed.
For example, in our work with Tasmea, Calumo is used to ingest transaction-level GL data across subsidiaries and map it to a unified chart of accounts, allowing simple consolidation that previously lived in large excel workbooks. It also allows trusted dashboards and management reporting. This foundation has also been used to capture, calculate and report ESG data using a simple (sophisticated under the hood) and consistent approach.
2. Consolidation-ready structures
If the business operates across multiple entities, the warehouse needs to do more than hold balances. It should support the structures required for group reporting:
- entity hierarchies
- ownership structures
- intercompany logic
- elimination rules
- management only adjustments
- multi-currency handling
- constant-currency handling
- management and statutory views where required
Without this, finance teams usually end up rebuilding consolidation logic outside the governed model, which defeats much of the purpose.
A common pattern we see is that businesses think they have centralised their data, but the hardest parts of consolidation are still being managed offline in spreadsheets or separate workbooks.
In our experience with Salta Properties, this was addressed by integrating NAV, multiple Xero entities, and MRI imports into a Calumo environment that supported automated eliminations and reporting across the group and for both Development and Investment Property portfolios. That is a good example of what consolidation-ready structure looks like in practice.
3. Budget, forecast, and scenario data
A Finance Data Warehouse should not stop at actuals.
If it is going to support planning and performance management properly, it also needs controlled structures for:
- budgets
- rolling forecasts
- scenario versions
- assumptions
- planning drivers
- plan versus actual comparisons
We often see finance teams managing budgets and forecasts in separate models with different logic, different definitions, and different assumptions. That makes reporting slower, weakens forecast confidence, and creates unnecessary reconciliation work.
In our experience, the strongest environments are the ones where actuals, budgets, forecasts, and scenarios all sit within the same governed finance structure.
A good example is Aware Super, where Sun GL and HR data are linked into Calumo for detailed reporting, budgeting, and forecasting, alongside a sophisticated cost allocation engine that replaced large, slow Excel workbooks. The same allocation engine is used for both Actuals and Plan scenarios, and the rolling forecast automatically picks up staff changes.
4. Workforce and operational drivers
A finance-only warehouse that ignores the operational drivers of performance is often too narrow.
Most finance teams need more than financial actuals. Depending on the business, they may need:
- HR and payroll data
- headcount and FTE metrics
- sales pipeline information
- project or job data
- valuation or asset-level operational data
- production or service delivery metrics
- time spent or work completed by staff
At Brydens BI, we often say that the right finance model is broad enough to support better decisions, but not so broad that it becomes unfocused or ungovernable.
The point is not to connect everything. The point is to connect what materially improves finance insight.
For example, in our work with Energy One, reporting is automated across Sage Intacct, HiBob, and HubSpot CRM so management can see finance, HR, and pipeline information across different regions in one environment. The introduction of constant currency options also means actual v plan P&L reporting across different global regions can easily include or exclude the impacts of FX.
Similarly, Acumentis combines Sage Intacct, Employment Hero, and an internal valuation system to support reporting, three-way rolling forecasts, and commission reporting down to employee level. In this case commissions are also calculated in the Finance Datawarehouse as that is where all the critical data lives and where Finance can review and manage it.
These are good illustrations of what happens when workforce and operational drivers are treated as part of the finance reporting model, rather than as disconnected side inputs.
5. A finance-owned business logic layer
This is where many projects succeed or fail.
A Finance Data Warehouse should contain the logic that makes the numbers trustworthy:
- account mappings
- hierarchy rules
- KPI definitions
- allocation methods
- treatment of one-off adjustments
- treatment of intercompany activity
- forecast and planning rules
- handling of changes in structure over time
- security, who can see what, and who can edit what
In our experience, the technology is often the easier part. The harder part is the modelling, metadata, mapping rules, and governance needed to keep the data meaningful as the business evolves.
That is why we believe this layer should be built for Finance and owned by Finance, with strong support from technical specialists. IT and data teams remain critical for platform, engineering, and security, but the meaning of the numbers cannot be left ambiguous or treated as an afterthought.
For example, in our work with Tasmea, the model supports the onboarding of new acquisitions while maintaining consistent mapping logic across subsidiaries. That is exactly the kind of requirement a finance-owned business logic layer should be able to handle.
6. Reporting and drill-through structures
A warehouse is only useful if it is designed for the outputs Finance actually needs.
That means it should support:
- board packs
- executive management reporting
- divisional and project reporting
- variance analysis
- drill-through to source logic
- repeatable monthly reporting structures
- on-demand, ad-hoc analysis
- easy integration with Excel
We often see reporting projects that focus heavily on visualisation, but not enough on structure. The result is that the reports may look nice, but the finance team still does a lot of manual work behind the scenes to explain and validate the outputs.
In our view, good reporting architecture should reduce explanation effort, not increase it.
A good example is Cromwell Funds Management, where Yardi data is linked into Calumo for periodic and on-demand updates, supporting consolidation, management reporting, budgeting, and rolling forecasts from a more controlled environment.
7. Governance, controls, and auditability
Finally, the warehouse must be governed.
That includes:
- controlled refresh processes
- role-based access
- version control around planning data
- auditability of calculations and outputs
- repeatable close and reporting processes
- clear ownership between Finance and technical specialists
In our experience, this is where the real long-term value comes from. A Finance Data Warehouse is not just about faster reporting. It is about creating confidence in the reporting process itself.
This also matters if the organisation wants to use automation or AI in finance. Without governance, those tools can amplify inconsistency rather than improve insight.
For example, in our work with Techtronic, Calumo supports structured forecast workflow, allocation logic, foreign currency handling, and both online and Excel-connected forecasting, while moving reporting into a more automated and governed environment. Different country teams have access to only their data, follow their own workflow, and centrally its easy to see where everyone is up to.
From finance data foundation to automation, and then carefully introduced AI
One of the biggest advantages of a Finance Data Warehouse built for Finance and owned by Finance is that it creates a practical path to benefits beyond reporting.
At Brydens BI, we often see organisations reach a point where the issue is no longer just month-end reporting. They also have spreadsheet-based finance processes that have become too important, too complex, or too slow to leave unmanaged.
This is where a governed finance data foundation becomes especially valuable.
Once the data model, mappings, hierarchies, and controls are in place, the same environment can be used to automate finance processes that are often still handled through fragile spreadsheet logic. Instead of rebuilding logic in separate files every cycle, the team can move repeatable processes into a controlled environment with shared data, consistent business rules, auditability, and automation.
We have seen this clearly in cases where finance teams were managing allocations, integrated operational reporting, or other high-value processes in Excel well past the point where Excel was the right long-term tool.
One example we have written about is a large superannuation fund where a spreadsheet-heavy allocation process had been taking 3 to 4 days at month end. By moving that logic into a more controlled environment with rule-driven allocations and automated journal generation, the process was reduced to under 30 minutes and fully allocated numbers became continuously available.
Another example is a diversified property and infrastructure client where we built a finance data warehouse in Microsoft Azure, integrating general ledger data with operational systems and using Calumo for reporting, driver-based modelling, and executive dashboards. That gave leadership a much clearer view of profitability and performance by project, asset, and business unit in one governed environment.
In our experience, this kind of foundation also creates the right conditions for the careful introduction of AI.
AI in finance is most useful when it is applied to well-structured, governed, finance-ready data. Without that foundation, AI can accelerate confusion just as easily as it accelerates insight. We see AI as something to introduce carefully, once Finance has control of the underlying data model and confidence in the business logic behind it.
That is why the sequence matters:
- build the finance-owned data foundation
- automate repeatable finance processes
- introduce AI selectively where it adds real value
In practice, that may mean using the warehouse first to automate allocations, reconciliations, commission logic, or integrated management reporting. Then, once Finance is confident in the structure and meaning of the underlying data, it becomes much easier to introduce more advanced use cases such as AI-assisted forecasting, anomaly detection, pattern identification, or draft commentary creation.
In our view, that is the right way to think about AI in finance. Not as a shortcut around governance, but as a benefit unlocked by good governance.
Which source systems should feed the model?
A common mistake is assuming the answer is “everything.”
In practice, we usually recommend connecting everything that materially improves finance decisions and can be governed properly. This doesn’t need to happen all at once. We typically do this in stages, sometimes over several years, sometime in weeks.
For most organisations, the core sources are:
- ERP or general ledger systems (normally GL transaction detail)
- payroll and HR systems
- planning inputs
- selected operational platforms (not everything, just what adds value)
- curated datasets from relevant CRM or pipeline systems
- curated datasets project, job, estimating or valuation systems
Our experience across clients shows that the right mix depends on what actually drives performance and decision-making. For some businesses that may mean a fairly traditional finance-led structure. For others, it may mean combining ERP, HR, CRM, valuation, or project systems into a more integrated reporting model.
The important point is that a Finance Data Warehouse is not defined by the number of feeds. It is defined by whether the data set is sufficient, reliable, and structured enough to support better finance decisions.
How this differs from a data lake
This distinction matters because the terms are often used interchangeably when they should not be.
A data lake is broad, raw, and flexible. It is useful for storing large volumes of enterprise-wide data, including data that may later support analytics, machine learning, and experimentation.
A Finance Data Warehouse is narrower, more structured, and more controlled. It is designed for precision: consistent reporting, trusted planning, repeatable consolidations, and finance-ready analysis.
In our experience, the two can absolutely coexist. In some environments, they should. But finance leaders should not assume that having a data lake means they already have a finance-ready reporting foundation.
That foundation still needs to be designed.
What good architecture looks like in practice
In practice, a good Finance Data Warehouse usually looks like this:
- governed source connections from core finance, HR, and selected operational systems
- a finance-centric data model with controlled mappings and hierarchies
- a planning and reporting layer that uses the same trusted structures
- secure role-based access and auditability
- the ability to evolve as the business changes
At Brydens BI, we have found that the best architectures are not the most complicated ones. They are the ones that support how Finance actually works.
The test is simple. Does the environment make reporting, planning, forecasting, and analysis easier, more controlled, and more scalable? If it does, the architecture is doing its job.
Common mistakes that make finance reporting slower, not faster
There are several patterns we see regularly.
The first is loading raw source-system structures into a reporting layer without curating them for finance use. That usually preserves source complexity instead of solving it.
The second is treating the project as a dashboarding exercise rather than a data and logic exercise. Reporting gets prettier, but trust does not improve.
The third is leaving key business rules undocumented or dependent on a small number of people. That creates risk and makes the environment harder to maintain as systems, acquisitions, restructures, and reporting needs change.
The fourth is failing to bring budgets, forecasts, and operational drivers into the same governed structure as actuals.
The fifth is assuming Excel must disappear entirely. In our experience, that is rarely the right way to think about it. The goal is not to ban spreadsheets. The goal is to remove fragility, improve control, and automate the processes that should no longer depend on manual workbook handling.
How to tell if your current environment is missing the basics
A useful self-test is to ask:
- Can we reconcile actuals quickly and confidently?
- Can we consolidate entities without heavy offline work?
- Are our allocation and adjustment rules documented and controlled?
- Can we compare plan, forecast, and actual from one trusted structure?
- Can we incorporate HR and key operational drivers without rebuilding models every cycle?
- Can we drill from reported outputs back to the logic behind them?
- Could we safely use AI or advanced analytics on this finance data without first cleaning up core definitions?
If the answer to several of these is no, the issue is often not reporting format. It is the absence of a proper finance data foundation.
Final thought
At Brydens BI, we believe a Finance Data Warehouse should be judged by practical outcomes, not architecture diagrams.
If it helps Finance close faster, trust the numbers more, produce board-ready reporting with less effort, run better forecasts, automate repeatable processes, and adapt as the business changes, then it is doing its job.
If it simply stores data but still leaves Finance reconciling spreadsheets, debating definitions, and rebuilding logic every month, then it is not.
The best Finance Data Warehouses are curated, governed, and built around how Finance actually needs to operate. That is why the structure matters so much. It is also why it becomes the foundation not just for better reporting and forecasting, but for finance process automation and the careful introduction of useful, controlled AI over time.
Suggested internal links
- The Business Case for a Finance Data Warehouse
- Building a Future-Ready Finance Function: Data Lakes, Calumo and the Finance Data Warehouse
- When Complex Finance Processes Need More Than Excel
- Calumo
- Clients
If you would like to assess whether your current reporting and planning environment has the right finance data foundations, we would be happy to help review the architecture, identify the gaps, and design a more governed path forward.